Learn how to run GPU accelerated functions on OpenFaaS while using Karpenter to save on infrastructure cost.
If you have ETL pipelines where certain processing steps require some AI model to run. Or if you are doing tasks like, audio transcription, image analysis with object recognition or natural language processing (NLP) for text extraction, then using GPUs can significantly speed up these AI-driven tasks.
GPU nodes can be expensive and you don’t want these nodes to sit idle costing you money when they are unused. In his post we will walk you through an example of how to build and run these kinds of workloads with OpenFaaS. We will see how OpenFaaS features like scale-to-zero and asynchronous invocation can be used together with Karpenter to add and remove GPU nodes on demand.
The impact of scale to zero GPUs on cost.
Loading a mid-size LLM over 4x GPUs with 96GiB of VRAM on a g6.12xlarge instance would work out to a cost of 3359 USD per month if the node is permanently added to the cluster. Per hour the same instance is only 4.6 USD. Therefore if you only needed it for 1 hour per day, you’d pay roughly 138 USD per month when you configure functions to scale down to zero. If you could get it on spot, the price drops to 1.9 USD per hour or 57 USD per month.
This post is the second part in a series covering OpenFaaS and Karpenter. Make sure to read the first part to learn what makes Karpenter a good match for OpenFaaS and a detailed guide on how to deploy and configure OpenFaaS and Karpenter on AWS EKS.
In this post we will configure the cluster to run GPU accelerated workloads and create a basic Python function to transcribe audio using the OpenAI Whisper model. We will show how to invoke the function asynchronously and get the result back for further processing.
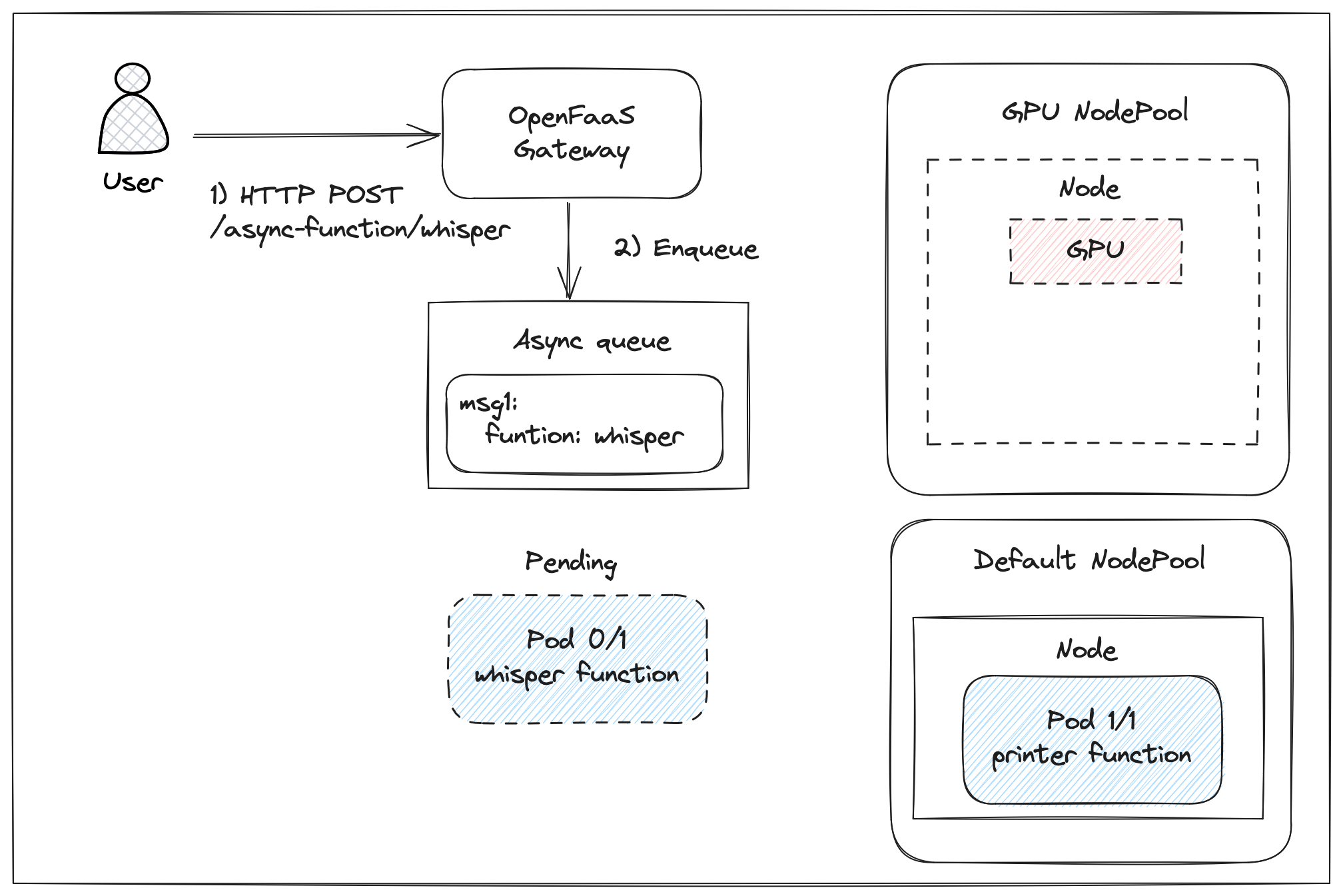
Invoke a function asynchronously to ensure the invocation is queued while a new GPU node is being provisioned.
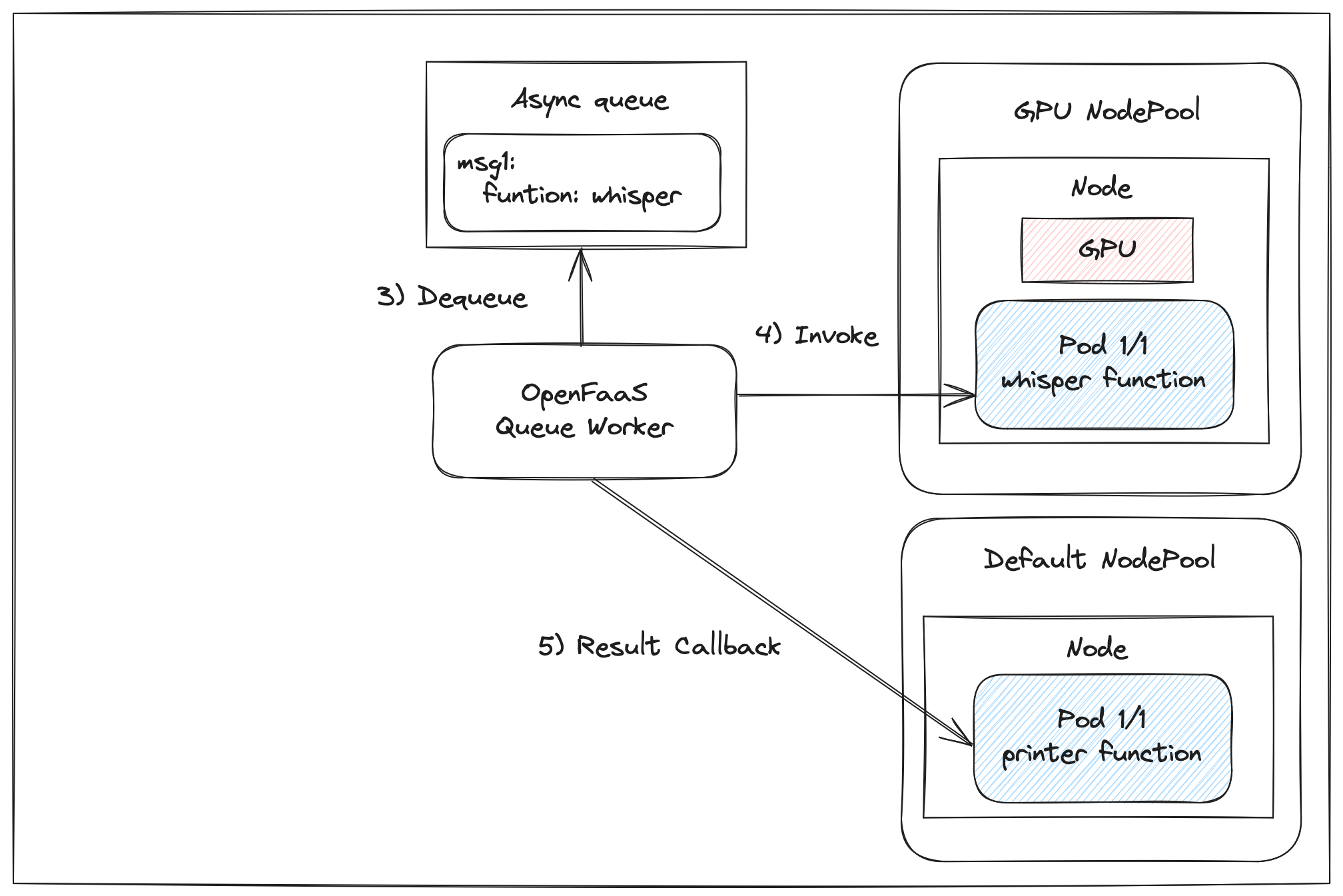
The queue worker will dequeue the request and attempt to invoke the function as soon as it is ready to accept requests. The result of the invocation is than posted back for further processing using the async callback url.
Prerequisites
To follow along and run the examples yourself we assume you already have an AKS cluster running with OpenFaaS and Karpenter installed and have a basic knowledge of how Karpenter works.
If you don’t have a cluster yet, read the first part of this series on OpenFaaS and Karpenter. There we show how to deploy and configure OpenFaaS and Karpenter on AWS EKS in detail.
AWS has service quotas that limit the types and number of EC2 instances that can be provisioned in each region. To run the examples in this post make sure your quotas are set high enough to allow scheduling g on optionally p category instances. We recommend increasing the limit
Prepare the cluster for GPU support
If you want to add nodes to the cluster that utilize GPUs you need to deploy the appropriate device plugin daemonset. In this example we will be using Nvidia GPUs only. However Kubernetes and Karpenter support more GPU vendors and types of accelerators. See the Karpenter docs for more.
Apply the Nvidia device plugin Daemonset:
kubectl create \
-f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.17.0/deployments/static/nvidia-device-plugin.yml
This command applies a basic static Daemonset which is enough for the basic use cases covered in this article. For more advanced configurations like shared GPU access or if you need more control over the installation it is recommended to deploy the device plugin via Helm instead.
Note: Installation and configuration of the Nvidia container runtime is not required. We will be configuring Karpenter to provision nodes with an appropriate EKS optimized Amazon Machine Image (AMI) that comes with the runtime installed.
Schedule GPU nodes with Karpenter
Karpenter supports accelerators such as GPUs. A GPU can be requested by simply adding resource requests to a Pod e.g. nvidia.com/gpu: 1. We will be creating a separate Karptner NodePool and NodeClass to match GPU resource requests.
Add a GPU node pool
Create a NodePool for workloads that need an Nvidia GPU:
cat > gpu-nodeclass.yaml << EOF
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: gpu
spec:
template:
metadata:
labels:
nvidia.com/gpu: "true"
spec:
taints:
- key: nvidia.com/gpu
value: "true"
effect: NoSchedule
requirements:
- key: kubernetes.io/arch
operator: In
values: ["amd64"]
- key: kubernetes.io/os
operator: In
values: ["linux"]
- key: karpenter.k8s.aws/instance-category
operator: In
values: ["g", "p"]
- key: "karpenter.k8s.aws/instance-gpu-manufacturer"
operator: In
values: ["nvidia"]
- key: "karpenter.sh/capacity-type"
operator: In
values: ["spot", "on-demand"]
- key: nvidia.com/gpu
operator: Exists
nodeClassRef:
group: karpenter.k8s.aws
kind: EC2NodeClass
name: gpu
expireAfter: 720h # 30 * 24h = 720h
disruption:
consolidationPolicy: WhenEmptyOrUnderutilized
consolidateAfter: 1m
EOF
-
The
spec.taintsis used to add a taint to GPU nodes. This prevents other Pods that don’t need a GPU from running on the nodes. -
In the requirements we tell Karpenter to allow both spot and on-demand instances. Karpenter will try to schedule spot instances first since they are usually cheaper and will only use the on-demand as a fallback. If your workload can not tolerate interruptions because an instance is reclaimed, request on-demand only.
-
We configure Karpenter to select from a range of GPU instances. By setting
karpenter.k8s.aws/instance-category, we require instances from thegandpcategories. We also setkarpenter.k8s.aws/instance-gpu-manufacturerto allow Nivida GPUs only. See the instance type reference in the Karpenter docs for all available types and labels to select instances best suited for your workload.
It is recommended to let Karpenter select from a wide enough range of instance types and avoid running out of capacity when some instances are not available.
Create a gpu NodeClass. This class is referenced by the NodePool and is used to select the EKS optimized Amazon Machine Image (AMI) that should be used when provisioning GPU nodes. This should be a GPU optimized AMI that includes the correct drivers and runtime.
export GPU_AMI_ID="$(aws ssm get-parameter --name /aws/service/eks/optimized-ami/${K8S_VERSION}/amazon-linux-2-gpu/recommended/image_id --query Parameter.Value --output text)"
export CLUSTER_NAME="openfaas"
cat > gpu-nodeclass.yaml << EOF
apiVersion: karpenter.k8s.aws/v1
kind: EC2NodeClass
metadata:
name: gpu
spec:
amiFamily: AL2 # Amazon Linux 2
role: "KarpenterNodeRole-"${CLUSTER_NAME}" # replace with your cluster name
subnetSelectorTerms:
- tags:
karpenter.sh/discovery: "${CLUSTER_NAME}" # replace with your cluster name
securityGroupSelectorTerms:
- tags:
karpenter.sh/discovery: "${CLUSTER_NAME}" # replace with your cluster name
amiSelectorTerms:
- id: "${AMD_AMI_ID}" # <- GPU Optimized AMD AMI
EOF
Apply both the NodeCall ans NodePool to the cluster:
kubectl apply -f gpu-nodeclass.yaml
kubectl apply -f gpu-nodepool.yaml
Run a GPU accelerated function.
While the OpenFaaS function spec allows setting cpu and memory resources, gpu resources can not be configured directly through the function spec. They need to be set using an OpenFaaS Profile. Profiles allow for advanced configuration of function deployments on Kubernetes and allow you to easily apply the configuration to multiple functions.
Create a Profile named gpu. This profile can be applied to functions by adding the annotation com.openfaas.profile=gpu. The spec from the Profile will be added
to the function deployment.
The gpu Profile needs to include resource request and limits for GPUs and a toleration that allows the function to run on GPU nodes.
kind: Profile
apiVersion: openfaas.com/v1
metadata:
name: gpu
namespace: openfaas
spec:
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
resources:
requests:
nvidia.com/gpu: 1 # requesting 1 GPU
limits:
nvidia.com/gpu: 1
Deploy the nvidia-smi function from the OpenFaaS store for testing:
faas-cli store deploy nvidia-smi \
--annotation com.openfaas.profile=gpu
Invoke the nvidia-smi function to verify it can make use of the GPU:
curl -i --connect-timeout 120 http://127.0.0.1:8080/function/nvidia-smi
Note that we explicitly increase the request timeout to 120 seconds. This is to make sure the request does not timeout while the function is getting scheduled. This larger timeout is required for the initial request because Karpenter has to provision a new GPU node. The function can only be started once the node is ready. During testing we saw adding a new node takes between 50 and 70 seconds on average.
The OpenFaaS gateway will hold on to the request while the function is pending. Once the Readiness probe has passed the request is forwarded.Any subsequent requests wont have this delay.
If the request is successful you should see the nvidia-smi output in the response.
Tue Jan 21 17:57:25 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.144.03 Driver Version: 550.144.03 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 Tesla T4 On | 00000000:00:1E.0 Off | 0 |
| N/A 23C P8 9W / 70W | 1MiB / 15360MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+
You can always check the number of GPUs available on nodes by running:
kubectl get nodes \
"-o=custom-columns=NAME:.metadata.name,GPU:.status.allocatable.nvidia\.com/gpu"
NAME GPU
ip-192-168-19-10.ec2.internal <none>
ip-192-168-35-233.ec2.internal 1
Tutorial: create a GPU accelerated function workflow.
In this section we are going to show you how to run a basic GPU accelerated function workflow. We will create a function that runs the Whisper speech recognition model to transcribe an audio file. The function takes a url to a file as the input, transcribes the files and returns the transcript in the response. The response will be submitted to the next function in the workflow for further processing.
This basic example is intended to show you how to:
- Use the OpenFaaS autoscaler and scale to zero capabilities for cost effective, on demand GPU node provisioning with Karpenter. GPU nodes are removed from the cluster to save cost when functions are idle.
- Use asynchronous invocations and callbacks to build a resilient function workflows. Invoke function asynchronously to handle, cold start delays when GPU nodes need to be provisioned. Use the async callback functionality to get the result from asynchronous invocations for further processing by a next function.
- Use concurrency limits and retries for efficient scaling and to prevent overloading the cluster.
Create a function
Create a new function using the OpenFaaS CLI.
# Change this line to your own registry
export OPENFAAS_PREFIX="docker.io/welteki"
# Scaffold a new function using the python3-http-debian template
faas-cli new whisper --lang python3-http-debian
This scaffolds a new function named whisper using the python3-http-debian template, one of the official OpenFaaaS python templates.
The function handler whisper/handler.py is where you write the custom function code. In this case the function retrieves an audio file from a url that is passed in through the request body. Next the whisper model transcribes the audio file and the transcript is returned in the response.
import os
import tempfile
from urllib.request import urlretrieve
import whisper
def handle(event, context):
models_cache = os.getenv("MODELS_CACHE", "/tmp/models")
model_size = os.getenv("MODEL_SIZE", "tiny.en")
url = str(event.body, "UTF-8")
audio = tempfile.NamedTemporaryFile(suffix=".mp3", delete=True)
urlretrieve(url, audio.name)
model = whisper.load_model(name=model_size, download_root=models_cache)
result = model.transcribe(audio.name)
return (result["text"], 200, {'Content-Type': 'text/plain'})
The first time the function is invoked it will download the model and save it to the location set in the models_cache variable. /tmp/models is used by default. Subsequent invocations of the function will not need to refetch the model.
It is good practice to only write to the
/tmpfolder from function and make the function filesystem read-only by settingreadonly_root_filesystem: truein the function stack.yaml. This provides tighter security by preventing the function from modifying the rest of the filesystem.
The function uses the tiny.en model by default but different model sizes can be selected by setting the MODEL_SIZE env variable for the function.
Add runtime dependencies
Our function handler uses the openai-whisper python packages. Edit the whisper/requirements.txt file and add the following line:
openai-whisper
Whisper relies on ffmpeg for audio transcoding. It requires that ffmpeg is installed it the function container as a runtime dependency. The OpenFaaS python3 templates support specifying additional packages that will be installed with apt through the ADDITIONAL_PACKAGE build arguments.
Update the stack.yaml file:
functions:
whisper:
lang: python3-http-debian
handler: ./whisper
image: docker.io/welteki/whisper:latest
+ build_args:
+ ADDITIONAL_PACKAGE: "ffmpeg"
Apply profiles
The function will need to apply the gpu profile that was created while preparing the cluster for GPU workloads. The profile sets gpu resource requests and adds the required tolerations to the function deployment. Add the com.openfaas.profile: gpu annotation to the stack.yaml file:
functions:
whisper:
lang: python3-http-debian
handler: ./whisper
image: docker.io/welteki/whisper:latest
build_args:
ADDITIONAL_PACKAGE: "ffmpeg"
+ annotations:
+ com.openfaas.profile: gpu
Configure scale to zero
The Karpenter gpu NodePool that we configured removes nodes when they are idle or when the resources are underutilized. Our function requests a GPU to run so as long as there are any function replicas holding on to these resource no nodes will get removed. To free up these resources and save money by removing GPU nodes from the cluster, functions can be configured to scale down to zero replicas when idle.
Scale down to zero is controlled by the OpenFaaS Pro autoscaler. By default the autoscaler does not scale functions to zero. This is by design and means that you need to opt-in each of your functions to scale down. Scale to zero for function is configured by setting the com.openfaas.scale.zero and com.openfaas.scale.zero-duration on a function.
Add the autoscaling labels to the stack.yaml configuration to scale down the function after 2 minutes of inactivity.
functions:
whisper:
lang: python3-http-debian
handler: ./whisper
image: docker.io/welteki/whisper:latest
build_args:
ADDITIONAL_PACKAGE: "ffmpeg"
annotations:
com.openfaas.profile: gpu
+ labels:
+ com.openfaas.scale.zero: true
+ com.openfaas.scale.zero-duration: 2m
The whisper function will be scaled down to zero replicas after 2 minutes if there are no more invocations. When Karpenter detects the GPU node is empty the node is removed from the cluster. This way you wont pay for idle GPU resources.
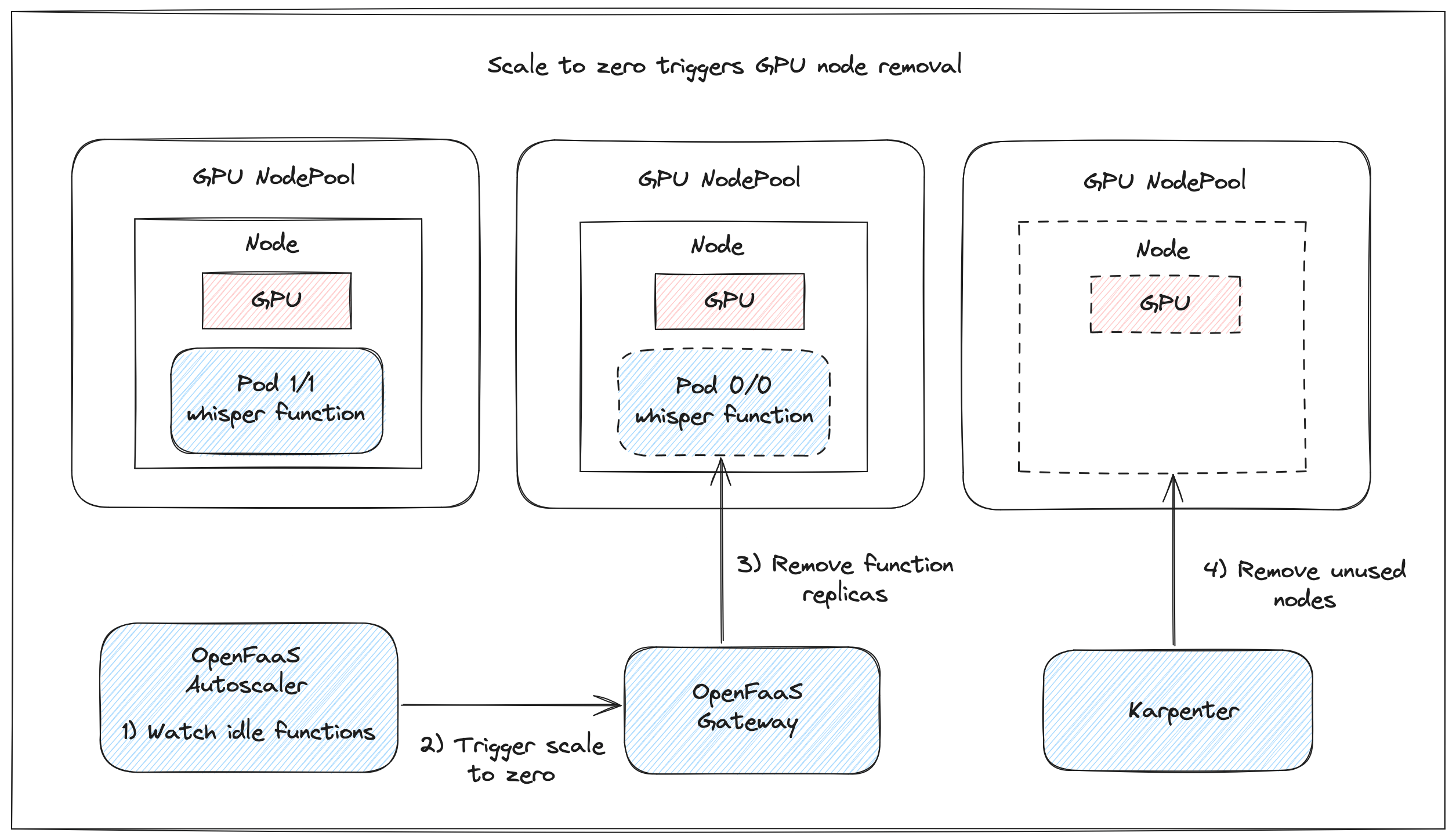
Conceptual diagram showing how an unused GPU node gets removed from the cluster by Karpter when the function running on the node gets scaled down to zero replicas by OpenFaaS.
Configure timeouts
It is common for inference or other machine learning workloads to be long running jobs. In this example transcribing the audio file can take some time depending on the size of the file and the GPU speed. To ensure the function can run to completion timeouts for the function and OpenFaaS components need to be configured correctly.
We will be increasing the timeout to 30min. Unlike AWS Lambda, which has a maximum runtime limit of 15 minutes, with OpenFaaS you can pick any value.
If you followed steps in our previous post, Save costs on AWS EKS with OpenFaaS and Karpenter, to set up your cluster the timeouts for the OpenFaaS core components should be set to 10 minutes. Make sure to increase these to match the longest function timeout, in this case 30 minutes. See: Core component timeouts
Update the stack.yaml file to set the appropriate timeouts for the function:
functions:
whisper:
lang: python3-http-debian
handler: ./whisper
image: docker.io/welteki/whisper:latest
build_args:
ADDITIONAL_PACKAGE: "ffmpeg"
annotations:
com.openfaas.profile: gpu
labels:
com.openfaas.scale.zero: true
com.openfaas.scale.zero-duration: 2m
+ environment:
+ write_timeout: 30m5s
+ exec_timeout: 30m
See the section on extended timeouts in our docs for more info.
Invoke the function asynchronously and capture the result
Before the function can be invoked it needs to be deployed to the cluster. The faas-cli can build and deploy the function using a single command:
faas-cli up whisper
We are going to invoke the function asynchronously and set the X-Callback-Url header to receive the result. In this example we will be sending the result to the printer function for simplicity. The printer function is one of our utility functions that just logs the request headers and body when invoked.
In a production pipeline the callback function could be the next step in the workflow that does some further processing of the result or uploads it to some storage solution like a database or S3 bucket.
Deploy the printer function:
faas-cli store deploy printer
Invoke the function asynchronously using curl:
curl -i http://127.0.0.1:8080/async-function/wisper \
-H "X-Callback-Url: http://gateway.openfaas:8080/function/printer"
-d "https://raw.githubusercontent.com/welteki/openfaas-whisper-example/refs/heads/main/tracks/track.mp3"
Monitor the logs of the printer function to see the result.
faas-cli logs printer -t
Note that it can take some time before we get back the result. As we saw in the first section of the article with the nvidia-smi function Karpenter needs to provision a new GPU node before the function Pod can be scheduled.
Since the function was invoked asynchronously there is no need to worry about setting the correct request timeout. The OpenFaaS queue-worker will try to invoke the function once it becomes ready. Any failures are retried with a backoff and the result is posted back to the URL that we set in the X-Callback-Url header.
Build production ready workflows
In the previous section we touched on the base concepts for creating an async GPU accelerated workflow by chaining functions together, using the async callback to get the result for further processing. In this section we will run through some of the extra things that need to be considered to make a workflow ready for production.
Trigger a workflow
The default, and standard method for interacting with functions is through http requests. Like we showed in the tutorial, a workflow can be triggered by simply calling it from your application. You might want to trigger a workflow based on other events like:
- Cron schedules - trigger functions upon a schedule.
- Database changes - trigger functions whenever a row in the database changes.
- S3 file uploads - trigger OpenFaaS functions when a new file is uploaded to a bucket.
OpenFaaS integrates with different event sources through event connectors.
If you are integrating with different AWS services, there is a connector available for AWS SNS and AWS SQS. You might also like one of our other post on integrating with AWS:
- How to integrate OpenFaaS functions with managed AWS services
- Trigger OpenFaaS functions from PostgreSQL with AWS Aurora
Model caching
One of the main things to consider when creating functions that run these types of AI workloads is where to store the ML models. Models are often large and should be cached between function invocations.
-
Fetch on first request
In the code example used in this post the model is fetched when the function is called the first time and cached for subsequent invocations. This has the disadvantage that the first invocation takes longer.
-
Fetch on Pod start
Another option is to download the model immediately when the function starts. Combine this with a custom readiness check to prevent Kubernetes from sending traffic to the function while the model is still getting fetched. See Custom health and readiness checks.
-
Add to container Image
Both of the previous methods have the disadvantage that the model has to be downloaded again each time a new function replica is created. As an alternative, the model can be pre-fetched and included in the function container image. This will result in larger images that can take longer to pull the first time but can make use of image layer caching. This improves cold starts when scaling up a function if the image or certain layers are already cached.
-
Include in AMI
In a setup with Karpenter where nodes are created and removed often there is a high likelihood an image is not present in the cache and has to be pulled anyway. To work around that you could take it one step further and create a custom AMI with pre-pulled images. The Karpenter NodeClass can be updated to use the custom AMI.
As you can see there are trade-offs for all of the options and there might be some future work for us here to further improve the platform for this type of use case.
Handle the result callback
In the tutorial we used the printer function to collect the result of an async invocation and log the result. While this is a handy function for debugging and experimentation in a production pipeline the result probably needs further processing.
- You could upload the result to an AWS S3 bucket, which might in turn trigger another function.
- You could send the result to a next function that runs another inference model or LLM to do further processing of the result.
While we used a second function to receive the X-Callback-Url call in this example, the target does not have to be a function but can be any http service running inside or outside the cluster.
OpenFaaS is very flexible and does impose little limits in how you chain functions together to create these types of pipelines. You can easily fan-out by having a function invoke multiple other functions and with some extra state management, fanning in is also possible.
We have written up some hands on examples of this kind of patterns, including storing results in S3, in other posts:
- Exploring the Fan out and Fan in pattern with OpenFaaS
- Generate PDFs at scale on Kubernetes using OpenFaaS and Puppeteer
Setting limits
Depending on the number of GPUs assigned to a function and the available memory for each GPU you might want to limit the amount of requests that can go to the function at once. Kubernetes doesn’t implement any kind of request limiting for applications, but OpenFaaS can help here.
To prevent overloading the Pod and GPU, we can set a hard limit on the number of concurrent requests the function can handle. This is done by setting the max_inflight environment variable on the function. When a function cannot accept any more connections due to the inflight setting, it will return a 429 error, which indicates the message can be retried at a later time. When the function is invoked asynchronously retries are handled automatically.
Update the stack.yaml file to apply such a limit to the whisper example function:
functions:
whisper:
lang: python3-http-debian
handler: ./whisper
image: docker.io/welteki/whisper:latest
environment:
write_timeout: 5m5s
exec_timeout: 5m
+ max_inflight: 6
To avoid any unexpected charges it might be good to set a limit on the number of GPUs in the cluster.
OpenFaaS sets a default limit of 20 replicas for a single function. This limit can be changed using the com.openfaas.scale.max autoscaling label.
While this already prevents the cluster from scaling excessively the number of GPU nodes Karpenter will try to add to the cluster depends on the number of function requesting GPUs and the number of GPUs requested by each function.
To set a fixed limit use the limits section in the NodePool spec.
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: gpu
spec:
limits:
nvidia.com/gpu: 10
This limit allows a maximum of 10 GPUs in total in the NodPool. If the limit has been exceeded, nodes provisioning is prevented until some nodes have been terminated.
Keep in mind that AWS has service quotas. This limits the types and number of EC2 instances that can be provisioned in each region. Make sure your quota are set high enough to reach your desired cluster size.
Conclusion
In this second part on OpenFaaS and Karpenter we wanted to show how to deploy functions that require a GPU on OpenFaaS, invoke them and get the result back for further processing. By combining Karpenter node provisioning with OpenFaaS autoscaling capabilities we ensure you don’t have to pay for idle GPU resources.
In the first section we prepared the cluster and configured Karpenter to run GPU accelerated workloads. The Nvidia device plugin was installed and a new Karpenter NodePool with matching NodeClass for GPU nodes was applied to the cluster. This NodePool enables Karpenter to provision GPU instances and dynamically add GPU nodes to the cluster when required.
In the second part of the article we showed you how to create and deploy a basic Python function that uses OpenAI Whisper to transcribe audio. We walked though the different configuration options required to run the function and discussed more advanced patterns and features like:
- Scale to zero to trigger Karpenter to remove unused GPU nodes.
- Invoking the function asynchronously to handle cold start delays when Karpenter has to add extra GPU resources to the cluster.
- Configure concurrency limiting to prevent overloading your GPU while still making sure all requests can run to completion.
- Use the async callback to get back the result and combine functions together to create pipelines.
Related blog posts:
- How to transcribe audio with OpenAI Whisper and OpenFaaS
- Fine-tuning the cold-start in OpenFaaS
- Exploring the Fan out and Fan in pattern with OpenFaaS
- Generate PDFs at scale on Kubernetes using OpenFaaS and Puppeteer
Reach out to us if you’d like a demo, or if you have any questions about OpenFaaS on AWS EKS, or OpenFaaS in general.

Han Verstraete
Associate Software Developer, OpenFaaS Ltd
